
Lab5
Forberedelser
- Les ukens kursnotater om lister og grafikk.
- Les kapittel 4 i Automate the Boring Stuff with Python. Dette er et ganske stort kapittel, og dekker mye vi har gått i gjennom så langt.
- Les utforskning 5 med eksempler som er spesielt relevante for denne laben.
Innlevering og automatisk retting
- Innlevering skjer via mitt.uib
- For å få bestått, må du:
- få 100% riktig av CodeGrade på oppgave 1, og
- få bestått oppgave 2 etter retting av gruppeleder
- Oppgavene 3, 4, 5, 6 og 7 er frivillige, men det er viktig å kunne løse slike problemer på eksamen.
- Du kan levere så mange ganger du vil. Siste innlevering telles.
Oppgave 1a
I filen uke_05_oppg_1.py skriv en destruktiv funksjon remove_threes(a) som har en liste a som parameter. Funksjonen skal mutere listen slik at alle forekomster av tallet 3 blir borte.
print("Tester remove_threes... ", end="")
# Test 1
a = [1, 2, 3, 4]
remove_threes(a)
assert(a == [1, 2, 4])
# Test 2
a = [1, 2, 3, 3]
remove_threes(a)
assert(a == [1, 2])
# Test 3
a = [3, 3, 1, 3, 2, 4, 3, 3, 3]
remove_threes(a)
assert(a == [1, 2, 4])
# Test 4
a = [3, 3]
remove_threes(a)
assert(a == [])
print("OK")
Så lenge det finnes en 3’er i listen: fjern en 3’er fra listen.
Oppgave 1b
I filen uke_05_oppg_1.py skriv en ikke-destruktiv funksjon every_fourth(a) med en liste a som input. Funksjonen skal returnere en ny liste med som inneholder hvert fjerde element fra a (begynn med det første elementet, altså elementet på indeks 0).
print("Tester every_fourth... ", end="")
# Test 1
a = ["a", "b", "c", "d", "e"]
assert(["a", "e"] == every_fourth(a))
assert(["a", "b", "c", "d", "e"] == a)
# Test 2
a = list(range(10))
assert([0, 4, 8] == every_fourth(a))
assert(list(range(10)) == a)
# Test 3
a = list(range(20, 1000))
assert(list(range(20, 1000, 4)) == every_fourth(a))
assert(list(range(20, 1000)) == a)
print("OK")
Opprett en resultatliste (som i utgangspunktet er tom)
Gå gjennom listen
amed en indeksert løkke. Dersom indeks er delelig med 4, legg til elementet i resultatlisten.
Oppgave 1c
I filen uke_05_oppg_1.py skriv en destruktiv funksjon halve_values(a) som tar en liste a med tall og muterer listen slik at alle tallene i listen halveres.
print("Tester halve_values... ", end="")
a = [1, 2, 3]
halve_values(a)
assert([0.5, 1, 1.5] == a)
print("OK")
Gå gjennom listen
amed en indeksert løkke. Inne i løkken muterer vi listen i den posisjonen indeks refererer til.
Oppgave 1d
I filen uke_05_oppg_1.py skriv en ikke-destruktiv funksjon unique_values(a) tar en liste a og returnerer en ny liste lik som a men hvor alle gjentagende forekomster av verdier er fjernet. Det vil si, de unike verdiene skal ligge i samme rekkefølge som de først opprådte i a.
print("Tester unique_values... ", end="")
# Test 1
a = [1, 1, 2, 1, 3, 3, 3, 2]
assert([1, 2, 3] == unique_values(a))
assert([1, 1, 2, 1, 3, 3, 3, 2] == a)
# Test 2
a = ["a", "b", "c"]
assert(["a", "b", "c"] == unique_values(a))
assert(["a", "b", "c"] == a)
print("OK")
Opprett en resultatliste (som i utgangspunktet er tom)
Gå gjennom listen
amed en løkke, og legg elementet fraatil i resultatlisten dersom det ikke finnes der fra før.
Oppgave 1e
I filen uke_05_oppg_1.py skriv en destruktiv funksjon add_list(a, b) som tar to like lange lister av tall a og b som input. Funksjonen skal mutere listen a slik at verdiene i listen a økes med verdiene i listen b på tilsvarende posisjoner.
print("Tester add_list... ", end="")
a = [1, 2, 3]
b = [4, 2, -3]
add_list(a, b)
assert([5, 4, 0] == a)
assert([4, 2, -3] == b)
print("OK")
Gå gjennom listen
amed en indeksert løkkeFor hver indeks, regn ut summen av verdiene fra
aogbmed den gitte indeksen.
Oppgave 2
Les kursnotatene om grafikk og følg installasjons-instruksjonene. Sjekk at du får til å tegne rektangler, ovaler og streker.
I denne oppgaven skal du levere inn to filer, uke_05_oppg_2.py som importerer uib_inf100_graphics og tegner fin figur, samt uke_05_oppg_2.png som viser et skjermbilde av programmet ditt. Figuren skal forestille et valgfritt motiv konstruert av streker, rektangler og ovaler. Du kan godt navngi kunstverket ditt med en kommentar i koden. For eksempel, her har du det kanskje snart berømte kunstverket «Gul sau med grønt hode»:
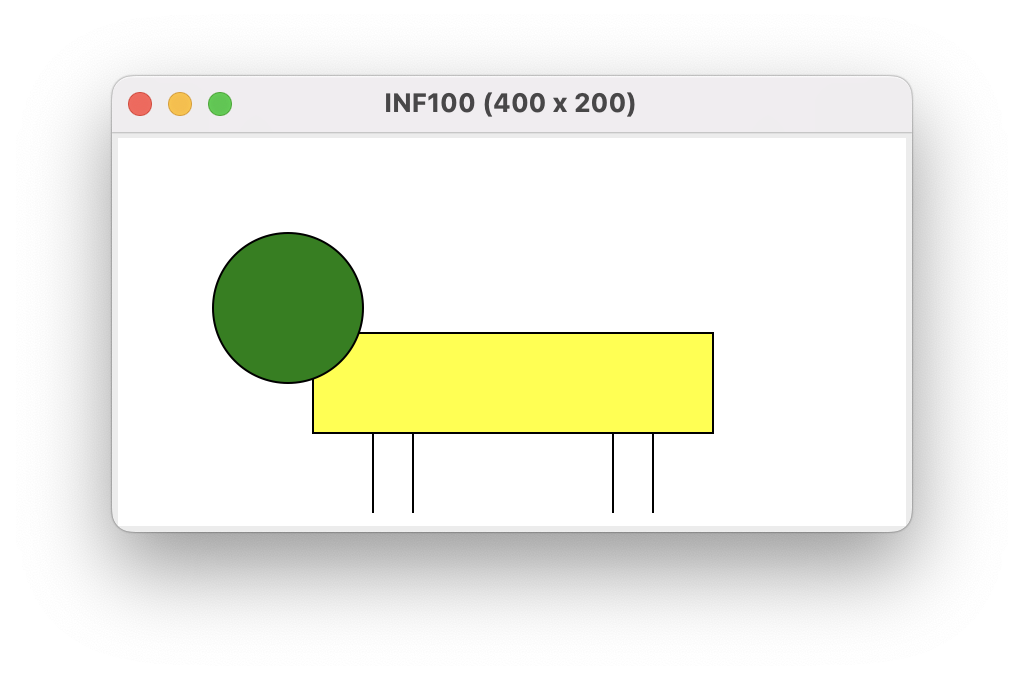
Kunstnerisk genialitet vil ikke være en del av vurderingen. Om du har vanskelig få å finne på et fint motiv selv, kan du gjerne kopiere sauen over (men bruk i det minste noen andre farger).
Windows: her finnes det et utall varianter. For eksempel:
win+shift+svil på de fleste Windows 10/11 åpne “Snipping Tool.” Tegn et rektangel rundt den delen av skjermen du skal ta bilde av. Bildet legger seg i clipboard som standard(?), men kan limes inn i f. eks. “Paint” og lagres som .png derfra.win+PrtScvil på en del Windows-versjoner ta et skjermbilde av hele skjermen og legge det i Snapshot -mappen som finnes inni bilde-mappen til din bruker (for eksempel C:\Users\yourname\Pictures\Screenshots).
Mac:
command+shift+4, og tegn så en en rektangel rundt den delen av skjermen du skal ta bilde av. Bilder legger seg på skrivebordet som standard.
Bonus:
- Ekstra vakre figurer vi kan vise frem neste forelesning.
- Figuren justerer seg om vinduet endrer størrelse, enten ved at den strekker seg, eller (litt mer komplisert) at den holder seg sentrert, eller (enda mer komplisert) beholder høyde-bredde-ration men endrer også størrelse.
Oppgave 3 (frivillig)
I filen uke_05_oppg_3.py lag en ikke-destruktiv funksjon sort_by_sign(a) som tar inn en liste a med helltall og returnerer en ny liste som består av
- først, alle de negative tallene i samme rekkefølgen de opptrådte i
a; - deretter, alle 0 -verdiene; og
- til slutt, alle de positive tallene i samme rekkefølge de opptrådte i
a.
For eksempel, hvis a er [3, -4, 1, 0, -1, 0, -2], skal funksjonen returnere listen [-4, -1, -2, 0, 0, 3, 1].
print("Tester sort_by_sign... ", end="")
# Test 1
a = [3, -4, 1, 0, -1, 0, -2]
assert([-4, -1, -2, 0, 0, 3, 1] == sort_by_sign(a))
# Test 2
a = [10, -10, -2, 0, 0, 30, 10]
assert([-10, -2, 0, 0, 10, 30, 10] == sort_by_sign(a))
# Test 3
a = [100, -10, -20, 1000, -1000, 10]
assert([-10, -20, -1000, 100, 1000, 10] == sort_by_sign(a))
print("OK")
Oppgave 4 (frivillig)
I filen uke_05_oppg_4.py lag en funksjon read_and_sort uten parametre som leser ett og ett heltall fra brukeren og lagrer dem i en liste. Funksjonen skal fortsette å lese verdier helt til brukeren skriver inn 0. Programmet skal ikke skrive ut noe så lenge det leser input.
Når programmet har lest 0, er lesefasen ferdig. Programmet skal nå skrive ut alle verdiene som er lest inn (unntatt 0) i rekkefølge fra minst til størst. For eksempel:
Input (skrevet av bruker) | Output (utskrift) |
I denne oppgaven er det viktig at du lar det være et kall til read_and_sort() på slutten av filen, slik at CodeGrade klarer å teste programmet ditt.
Oppgave 5 (frivillig)
En DNA-sekvens (f.eks ATAGCAGT) sammensettes av 4 ulike «baser», som beskrives med A, T, G og C. Under replikasjon av sekvensen kan hver base settes sammen med eksakt én av de andre: A med T, og C med G.
original ------->
ATAGCAGT
||||||||
TATCGTCA
<------- complement
Slik får man en «komplementstreng» av den opprinnelige DNA-sekvensen.
Det vanlig å skrive ned komplementstrenger baklengs, slik at i vårt eksempel sier vi at komplementstrengen til ATAGCAGT er ACTGCTAT (ikke TATCGTCA).
I filen uke_05_oppg_5.py lag en funksion som heter complement(seq) som returnerer komplementstrengen av en DNA-sekvens. Funksjonen skal ta inn en streng seq som representerer en DNA-sekvens, og skal returnere sekvensens komplementstreng.
print("Tester complement... ", end="")
assert("ACTGCTAT" == complement("ATAGCAGT"))
assert("TAGTATCTAGT" == complement("ACTAGATACTA"))
assert("ACACAGCTGCAT" == complement("ATGCAGCTGTGT"))
print("OK")
Del opp oppgaven i to steg: (1) regn ut den “fremlengse” komplementstrengen; (2) reverser den.
For å regne ut den fremlengse komplementstrengen, benytt en løkke over symbolene i
seqog inne i løkken, benytt betingelser for å legge til riktig symbol i en resultatstreng.For å reversere strengen kan du benytte beskjæring med negativt steg.
Oppgave 6 (frivillig)
En streng sub er en ikke-kontinuerlig substreng av strengen s dersom alle tegnene i sub opptrer i samme rekkefølge i s. For eksempel er "foo" en ikke-kontinuerlig substreng av "good for nothing":
good for nothing
|| |
fo o
I filen uke_05_oppg_6.py, skriv en funksjon non_contigous_substrings(s) som tar inn en streng s og returnerer en liste med alle ikke-kontinurelige substrenger av s.
print("Tester non_contigous_substrings... ", end="")
# Test 1
# Merk: rekkefølgen på elementene i listen betyr ingenting,
# siden begge listene sorteres før de sammenlignes
assert(sorted([
"", # Den tomme strengen er alltid en substreng
"a", "b", "c", "d",
"ab", "ac", "ad", "bc", "bd", "cd",
"abc", "abd", "acd", "bcd",
"abcd",
]) == sorted(non_contigous_substrings("abcd")))
# Test 2
assert(sorted([
"",
"f", "o", # Merk: "o" opptrer bare én gang
"fo", "oo",
"foo",
]) == sorted(non_contigous_substrings("foo")))
print("OK")
For å se løsningen på denne oppgaven, hjelper det å observere følgende:
- Dersom vi på magisk vis vet løsningen for problemet når strengen vi jobber med er ett symbol kortere, kan vi utnytte den: alle substrenger for den ett symbol kortere strengen, er også substrenger for den lengre strengen. De eneste substrengene som da “mangler” er de som slutter på det siste tegnet i strengen.
- Begynn med å opprette en resultatliste som inneholder kun den tomme strengen (den tomme strengen er alltid en substreng).
- Gå gjennom tegnene i
smed en løkke; én iterasjon av løkken er ansvarlig for å legge til alle ikke-kontinuerlige substrenger som slutter på dette tegnet. - Hvilke valg finnes det for begynnelsen på de substrengene vi nå skal legge til? Det er nettopp de strengene som finnes i resultatlisten fra før.
- Å utvide en liste samtidig som man løkker over listen krever at man holder tungen beint i munnen. Det kan være lettere å opprette en hjelpeliste
substrings_ending_at_chvor man legger til bare dem som slutter på gitte tegn, og så utvide resultatlisten med denne listen når den er ferdig utregnet. - Benytt funksjonen
unique_valuesdu skrev i oppgave 1 for å fjerne duplikater.
Hvor mange ikke-kontinuerlige substrenger finnes det for strengen
"good for nothing"?